Presentación del curso
1. La estrategia tecnológica tras el modelo de la Startup
2. Gestionando un proyecto tecnológico en una Startup
3. La gestión del equipo técnico humano en una Startup
4. Asegurando el control y la calidad de tu producto tecnológico
5. El entorno físico y cultural que potencia la productividad
5. El entorno físico y cultural que potencia la productividad:
Introducción
Queremos comenzar esta lección compartiendo con vosotros un estudio sobre cómo influyen los entornos en los que trabajamos en nuestro día a día respecto al trabajo realizado. Hace ya unos años, en 1985, DeMarco y Lister crearon los “Coding War Games”, una competición que premiaba la velocidad y calidad del desarrollo software y en la que participaron 166 desarrolladores de 35 organizaciones diferentes. Entre otras conclusiones, la competición se usó como un experimento para estudiar hasta qué punto el entorno físico influye en la obtención de resultados.
Los organizadores de la competición pidieron a los participantes que les proporcionaran información sobre las características de su entorno físico de trabajo, concluyendo el estudio en que los mejores desarrolladores software fueron los que además disponían de mejores espacios físicos de trabajo, con menos interrupciones, llamadas de teléfono, mayor privacidad, etc. Hasta tal punto que los desarrolladores que ocuparon el 25% de las mejores posiciones, y que disponían de los mejores entornos físicos, obtuvieron una productividad 2,6 veces superior a aquellos que ocuparon el 25% de peores posiciones.
La frecuencia con que se olvida la influencia del entorno físico en la productividad se ha convertido en uno de los principales problemas de productividad en las organizaciones de desarrollo software.
También son curiosas las experiencias que hemos tenido trabajando en sótanos a lo largo de nuestra carrera profesional y las personas que se sienten identificadas cuando en los cursos, charlas o congresos tratamos este tema y se acercan a decirnos: ¡yo también he programado en un montón de sótanos!
Curioso, ¿será algo identificativo de la profesión? ¿De los que hemos vivido en modo body shopping trabajando para empresas en las que sí había mucho trabajo para nosotros pero nunca sitio? Uf, esperamos que no, que ya no sea así, y que esto sólo haya sido anecdótico.
Pero que no os quede una mala sensación, que no, en serio, seguro que los que estáis leyendo esto y también habéis disfrutado de un sótano sabéis lo que un sótano une a la gente, “team building” de sótano que le llaman algunos gurús, el compañerismo que genera (va en serio), las buenas historias que da para contar luego, para poner fotos de sótanos en un Power Point.
Cirillo, F. (2009). The Pomodoro Technique. Lulu Enterprises Incorporated
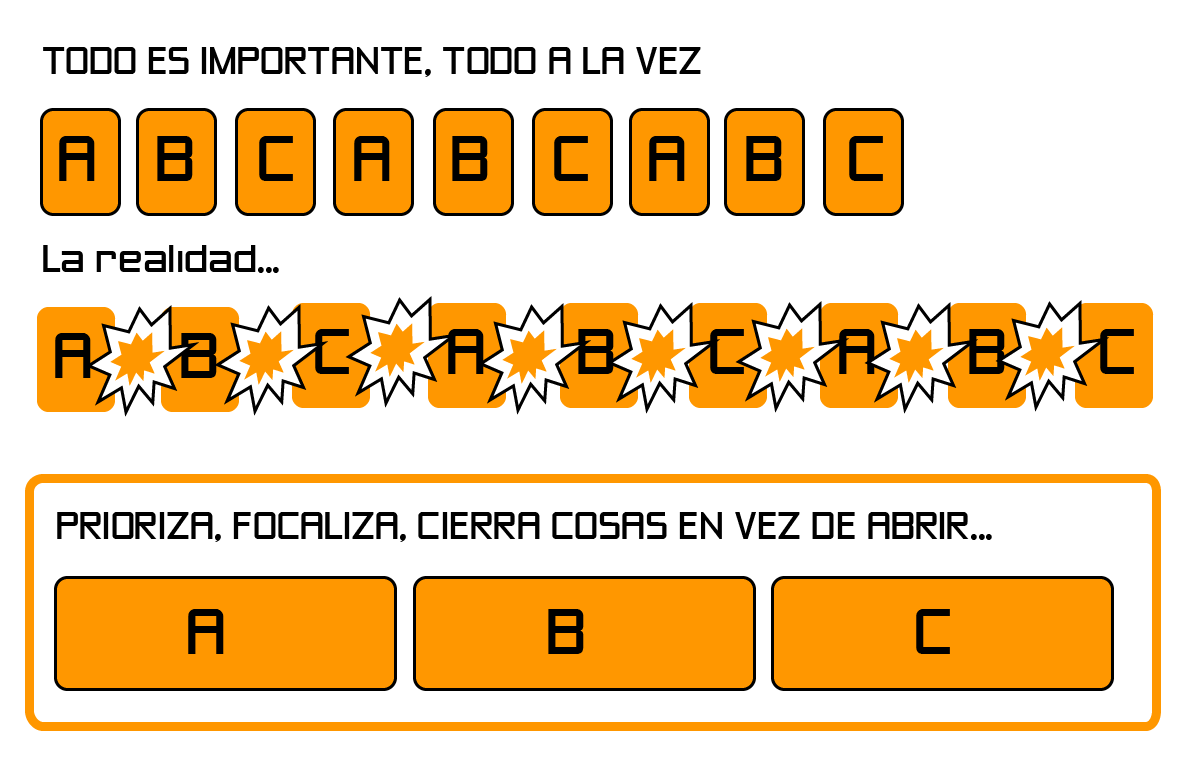
Tener muchas tareas abiertas a la vez merma la productividad
Una de las cosas que, en lo referente al equipo, más se enfatizan en Scrum, agilidad, y en Lean – Kanban, es el peaje que supone la multitarea para la productividad. En muchas empresas, a los equipos se les asigna más de un proyecto a la vez, se asignan múltiples tareas a la vez, etc., y cambiar de una tarea a otra daña la velocidad y la productividad.
Y quien más inspiró estas ideas en el mundo del software fue Clifford Nass, profesor de comunicación en la universidad de Stanford y pionero en investigar cómo los seres humanos interactúan con la tecnología.
Desgraciadamente, Clifford Nass murió el 2 de Noviembre de 2013, a los 55 años, debido a un ataque al corazón.
Cuando Clifford se incorporó como profesor de universidad, se sintió alarmado por el gran número de gente que utilizaba móviles, ordenadores y otros dispositivos similares a la vez que realizaba otras tareas. Mucha gente, además, afirmaba que era capaz de hacer perfectamente ambas tareas a la vez, asegurando que así aprovechan más el tiempo que haciendo una sola tarea.
Por ello, el profesor Clifford realizó un estudio (que se convirtió en uno de los más famosos de su carrera), analizando si eso era verdad. Concluyó que no solo ese perfil de personas no era capaz de realizar esas tareas igual de bien que si solo estuvieran haciendo una actividad, sino que además, el hecho de acostumbrarse a “realizar” dos tareas simultáneas había hecho que la capacidad de atención de esas personas disminuyera. De esta forma también observaron que las personas con este perfil tenían más dificultades para concentrarse que el resto.
Es por ello que Clifford, consultor de grandes empresas como Microsoft, Toyota, BMW etc., siempre estuvo en contra de la multitarea, defendiendo que obligar a los trabajadores a realizar varias tareas en paralelo disminuye su productividad.
¿Cuál es la mejor manera de organizar la sala y mesas de un equipo de desarrollo software?
Recuerdo que en una de las empresas de desarrollo en las que las que trabajé, hará unos 6 años, los puestos de trabajo, las mesas de todos, estaban dispuestas en dos grandes filas, dejando un pasillo en el centro.
Desconozco cuál fue el origen, pero un día en aquel pasillo aparecieron dos balones, uno de fútbol y otro de rugby. Y ello degeneró en la costumbre de que cuando alguien volvía del servicio le daba una patada a uno de los balones, y si coincidía que alguien más pasaba por allí… pues hasta se organizaba una “pachanga” (dícese de partido de fútbol informal) en el pasillo.
Había responsables de la empresa que veían aquello “cool”, molaba, porque era un “rollo” tipo Google. Servía para relajar, quitar estrés, daba imagen moderna, etc.
Pero no sé si aquellos responsables llegaron alguna vez a ser conscientes de que aquello también servía para romper la concentración de 30 personas, que acababan siendo el público de las “pachangas”. Y supongo que tampoco eran conscientes de que interrumpir a quien programa, o al que realiza cualquier actividad intelectual, hace que su productividad caiga (más de lo que imaginas).
Se habla de que se pierden una media de 15 min de trabajo de una persona concentrada cuando es interrumpida (Parnin y Rugaber publicaron en 2010 un trabajo sobre este tema), dos “pachangas” por día, 2 * 15 min = 30 min, por 30 personas, 900 min de trabajo perdidos por día, que son 15 horas al día, 75 horas a la semana, casi el trabajo de dos personas totalmente perdido a la semana .
Nos encantan las oficinas con juegos y salas de recreación, modernas, etc. Pero, por favor, separar las salas de recreo de los lugares de concentración.
Partiendo de la premisa que comentamos antes de que interrumpir a quien programa, o al que realiza cualquier actividad intelectual, hace que su productividad caiga (más de lo que imaginas), la oficina en la que un grupo de desarrolladores (o cualquier grupo de profesionales que realicen tareas que requieran concentración) trabaje debiera ayudar a eso, a evitar las interrupciones y la falta de concentración.
Aspectos generales a considerar en el entorno de trabajo
Uno de los aspectos fundamentales para un buen entorno de trabajo es que no haya ruido. Por tanto, elementos como puertas, aislantes de ruido, algún mecanismo para evitar las interrupciones entre los propios compañeros (en algunas empresas se utilizan cascos para indicar que no puedes ser interrumpido en ese momento), se hacen indispensables.
Un espacio iluminado con luz natural y con ventanas, también incrementa la productividad. Por otra parte, es primordial que la gente esté cómoda, con espacio suficiente para trabajar, pasar de tener 1 monitor a 2 monitores aumenta la productividad, y que cada uno pueda personalizar su entorno de trabajo para sentirlo más suyo.
¿Cubículos, despachos privados, salas de reuniones?
También está la opción de poner las mesas sin ningún elemento de separación entre las mismas, da más sensación de amplitud, pero eso solo se recomienda a aquellos cuya cultura de empresa es consciente del impacto de las interrupciones… y saben gestionarlas.
Más allá de la opción anterior, está la típica práctica de usar cubículos. Facilita la comunicación cara a cara, no hay puertas, es más rápido llegar a los sitios o a las mesas de otros compañeros, etc.
La siguiente opción, que nosotros apenas hemos visto, es que cada persona tenga un despacho. Tener un espacio con una puerta, disminuye radicalmente las interrupciones. La principal desventaja usar despachos es el sentimiento de soledad. Y lo otro, por lo que entendemos que esta opción casi nunca te la vas a encontrar, es que es más costoso, requiere más espacio físico.
En cualquiera de los anteriores es necesario complementar estos entornos con salas de reuniones para actividades que requieran trabajo en equipo, evitando molestar al resto del equipo. Y espacio para relajarse (con sofás, etc.).
Experiencias propias
Hace tiempo que nosotros, en nuestro entorno de trabajo, nos pusimos la norma de que cuando alguien quiere algo de otro se lo escribe por chat, en vez de gritárselo y hacer que el resto de la gente gire la cabeza y empiece a opinar sin necesidad. También, al pedirnos las cosas por chat, el que responde no tiene por qué contestar inmediatamente, interrumpiendo aquello en lo que estaba.
No hay una forma perfecta de organizar el entorno de trabajo, y al final lo que más influye es la cultura de la organización, y que el equipo sea consciente del impacto de las interrupciones.
No deja de ser una lástima pasar por empresas y empresas, y escuchar aquello de “mañana trabajaré desde casa (o en la biblioteca) porque tengo que terminar tal cosa, y si me quedo aquí en la oficina, no la termino”.
La separación física entre los miembros de un equipo impacta en su rendimiento
Durante una serie de conversaciones de hace un par de semanas, en el contexto de ayudar a una organización a mejorar su proceso siguiendo principios ágiles, concretamente un equipo distribuido por varios países, y la pregunta típica… “Javier, ¿crees que la distancia física entre los miembros del equipo impacta en el rendimiento del mismo?”
Ya sabéis, aquello de que el desarrollo software, que la ingeniería de software, que, en general, hacer cualquier trabajo del conocimiento, que todo aquello se realice por completo e íntegramente en el mismo lugar, todos juntos, en un único edificio de oficinas, pasó a la historia.
Sí, sí, sé que aún hay sitios más tradicionales, más clásicos, que aún se pueden permitir que todo el mundo trabaje de 9:00 a 18:00 en la misma sala, juntos, pero veremos en unos años cuantos quedan… o cuantos aguantan trabajando así… o cuanta gente aguanta trabajando así (me vuelve a la cabeza aquello de horas en la oficina vs ideas y conocimiento aportado).
Sin embargo, la distancia en la ingeniería de software, y prácticamente en cualquier trabajo del conocimiento, ha tenido de siempre un enorme impacto en los equipos: la distancia importa.
A más distancia, más problemas suele haber y por ello más cuidado debemos tener a la hora de cuidar la comunicación. Y no estoy hablando de separaciones de miles de kilómetros, la misma persona de la conversación que te comentaba al comienzo, y que inspira este texto, ya me comentaba que “incluso el que miembros del equipo estén en plantas diferentes del edificio está impactando en que los equipos lleguen a ser verdaderamente multifuncionales, ya que muchas veces lo de tener que moverse por el edificio hace que se reduzca la comunicación“.
Y la comunicación, cómo facilitar y hacerla lo más eficiente posible, es otra de esas cosas (al igual que le pasa a los entornos físicos, las interrupciones, etc.) que impacta mucho y se cuida poco. Fíjate que de hecho Dewayne Perry (aquí el artículo) y sus colegas hicieron hace ya sus años un estudio en el que observaron que los desarrolladores pasan más de la mitad de su tiempo en actividades que incluyen “algún tipo de interacción con otras personas”.
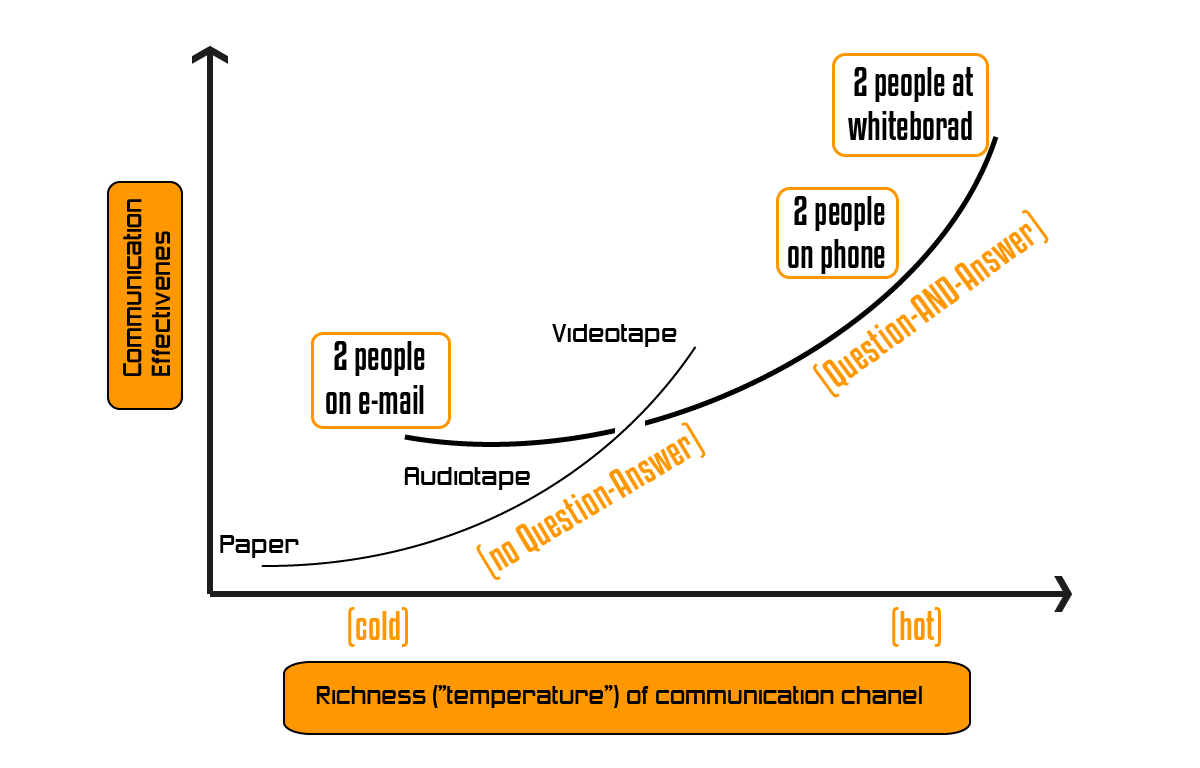
Hay una popular gráfica de Alistair Cockburn (te dejo la entrevista que tuve la suerte de hacerle hace un tiempo), que muestra los efectos de la distancia en referencia a los medios de comunicación usados: lo más eficiente es estar todos físicamente frente a una pizarra. De hecho Cockburn sugiere que “el equipo debe estar sentado con una separación no superior a la longitud de un autobús escolar”.
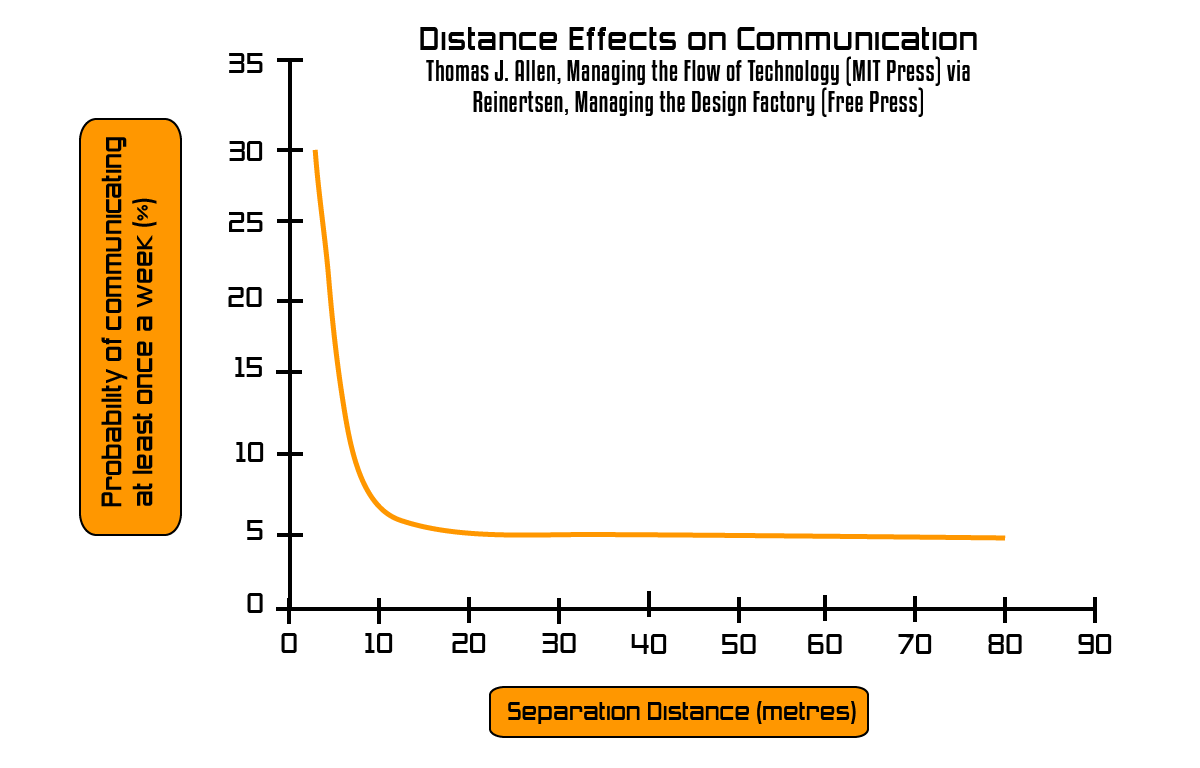
Otra popular curva sobre el tema es la curva de Allen, de 1977, que muestra que cuando las personas se separan a una distancia mayor a 10 metros la probabilidad de que se comuniquen al menos una vez a la semana cae al 10%.
Aunque la gráfica es antigua, y en aquellos tiempos no había la tecnología de ahora, Allen comentaba que en los últimos años la tecnología no ha podido hacer que esto mejorase mucho más.
Y es lo que también argumenta uno de los patrones Scrum, el Collocated Team, que habla de cómo si los miembros del equipo que están separados físicamente las cosas pueden funcionar de manera menos efectiva.
Dicho esto, y ya siendo conscientes y sabiendo que “sí”, que la distancia importa, que tiene impacto, lo ideal es que el equipo esté junto, lo más próximo que puedas, y que, si no puede ser, al menos, que seas consciente del impacto de la distancia y que por ello pongas especial atención en cómo mejorarla y fomentarla.
¿Es mejor que el equipo trabaje desde casa o que trabaje en la oficina?
En febrero de 2013, Marissa Mayer, la recién nombrada CEO de Yahoo, envió un comunicado a sus empleados diciéndoles que el trabajo de desde casa se había acabado, a partir de ese momento todo el mundo debía trasladarse a las oficinas. La principal razón de dicha decisión fue que “las personas son más colaborativas e innovadoras cuando están juntas y las mejores ideas surgen de unir ideas diferentes.” No obstante, el sentido común, la experiencia de los que trabajamos algunos días desde casa y gran número de estudios confirman que las personas que trabajan de forma remota son, en promedio, más productivas que las que trabajan en la oficina.
Hay varias razones para ello, para que sea normalmente más productivo el trabajo desde casa, principalmente que se eviten los desplazamientos (tiempo que puedes invertir en dormir más, pasear o trabajar más horas, cualquiera de los casos genera más productividad que estar sentado en el coche o ir de metro en metro) y que se evitan distracciones e interrupciones.
Y de ahí vienen frases que por más veces que escuchamos, y mira que las escuchamos, no dejan de sorprendernos: “me escondo en una sala de reuniones para trabajar”, “voy a trabajar a casa para poder hacer algo”, “me voy a una biblioteca para terminar el trabajo”, etc.
Pero, efectivamente, como decía Mayer, el aislarse no potencia la comunicación ni la creatividad, que es clave para una organización basada en el conocimiento, así que lo ideal no es ni lo uno ni lo otro… es una combinación de ambos.
Las opciones aquí son múltiples, nosotros hemos visto de todo. Por un lado, si bien son los menos, hay quien potencia el trabajo desde casa con comunicación vía herramientas online, pero hay que decir que un “skype” no es comparable con un cara a cara.
Curiosamente, otras empresas se aferran a que el trabajo en casa no sirve, les entra el miedo de que sus empleados en casa no trabajen (siendo esta política muchas veces una falta de confianza en los equipos y/o que los gerentes no disponen ni han pensado en cómo medir la productividad desde casa) y el trabajo en casa se prohíbe. Lo más curioso son aquellas organizaciones que trabajan así pero, además, propician oficinas y entornos ruidosos y con interrupciones, sin posibilitar entornos físicos para la concentración.
Y luego están los pocos, que suelen ser empresas medianas – pequeñas, que en nuestra opinión aplican la mejor opción… una combinación de ambos, trabajo en casa y en oficina. El trabajo en casa suele ser algunos días predefinidos, para coordinar a todo el mundo, o a criterio de la persona.
4. Asegurando el control y la calidad de tu producto tecnológico:
Introducción
Queremos comenzar esta lección compartiendo con vosotros las razones por las que la calidad software debe importarte.
1. Calidad del producto software no es lo mismo que testing
Que el software “funcione” (lo que normalmente intentas saber con el testing) no significa que por ello el producto esté bien hecho. Y si está mal hecho, no te vas a dar cuenta si no lo miras por dentro (miras sus fuentes, código, diseño, cómo de mal o bien está programado, si está muy acoplado, etc.), es decir, si no miras lo que se llama calidad del producto software.
2. La calidad del proceso no garantiza la calidad del producto
En el desarrollo software, de entre las diferentes perspectivas con que se puede observar la calidad, hay dos especial y tradicionalmente importantes: la calidad del producto en sí y la calidad del proceso para obtenerlo (o actividades, tareas, etc., para desarrollar y mantener software). Dos dimensiones esenciales, estudiadas desde hace tiempo por los grandes “padres” de los modelos y teorías de calidad en general y también aplicables a la construcción de software, y que giran e interactúan en torno a la idea de que, como comenta Humphrey, “padre” del modelo CMMI, “la calidad del producto está determinada por la calidad del proceso usado para desarrollarlo” puedes leer más aquí.
Aunque en el área del desarrollo software, que siempre ha ido un poco más atrás en temas de calidad, y en España, que en los últimos años se ha empezado a tratar en las empresas este tipo de aspectos, la popularidad e importancia a nivel industrial ha recaído casi por completo en los modelos de calidad de procesos, destacando el conocido modelo CMMI, que en los últimos años se ha extendido considerablemente.
Así modelos de calidad de procesos como CMMI son bastante populares en el mundo del desarrollo, y se están convirtiendo poco a poco en requisito imprescindible para un centro de desarrollo o fábrica software. En algunos casos, hasta el punto en que se ha llegado a asumir que cumplir cierto modelo o nivel de madurez de procesos asegura productos de calidad (que es lo más importante para ciertas empresas y entidades, sobre todo si han externalizado el desarrollo, donde lo que reciben periódicamente son productos de desarrollos de sus proveedores). Pero ¿realmente es garantía suficiente? ¿Una certificación sobre la calidad del proceso garantiza un producto de calidad?
Con respecto a este tema ha habido mucha controversia. Por ejemplo, hace tiempo comentaban Kitchenham y Pfleeger en un artículo en IEEE software que la principal crítica a esta visión es que hay poca evidencia en que cumplir un modelo de procesos asegure la calidad del producto, la estandarización de los procesos garantiza la uniformidad en la salida de los mismos, lo que “puede incluso institucionalizar la creación de malos productos”. Más recientemente Maibaum y Wassyng, en Computer, comentaban, siguiendo la misma línea, que las evaluaciones de calidad deberían estar basadas en evidencias extraídas directamente de los atributos del producto, y no en evidencias circunstanciales deducidas desde el proceso. Un proceso estándar, o institucionalizado, según sea la terminología del modelo de uso, no necesariamente concluye con un producto de calidad.
Si bien modelos como CMMI han gozado de mucha popularidad, no por ello los modelos o estándares de calidad de producto tienen menos madurez, destacando el menos popular pero igualmente importante ISO 9126, o la nueva serie ISO 25000, que especifica diferentes dimensiones de la calidad de producto.
En nuestra experiencia nos hemos encontrado bastante frustración en ciertas empresas debido a las esperanzas depositadas en los modelos de calidad de procesos que ofrecían sus proveedores y que finalmente no han servido como garantía de calidad de los productos que recibían.
Tener un “sello” de CMMI no siempre asegura un producto software de calidad. Así es. El “sello” es una evidencia “indirecta” de calidad, la calidad del producto software es evidencia “directa”. El sello, la certificación, evaluación, o como cada uno lo llame (para más detalles tienes la guía de supervivencia CMMI), en modelos como CMMI…
a) Se basa en un muestreo (no se ven todos los proyectos de la empresa), así que puedes tener mala suerte y que te toque un proyecto – equipo de desarrollo que no se evaluó.
b) Las auditorías CMMI no miran la calidad del producto software, sólo miran si se cumplen buenas prácticas del proceso, si se gestionan requisitos, si se verifica, si se planifican los proyectos, etc., pero no si esos requisitos tomados están bien, si ese plan de proyecto está bien… y mucho menos ¡cómo está el código!
c) Si eres un cliente y contratas a alguien porque tiene algún CMMI te mostrará un “sello” concedido en el pasado, y tu producto te lo entregará muchos meses después de la concesión del “sello” y en ese tiempo pueden pasar muchas cosas.
4. La mala calidad del producto siempre tiene un coste
Porque la mala calidad del producto software (es decir, código espagueti, código repetido, diseño acoplado, etc.) siempre, siempre, alguien la paga (euros), tiene un coste (lo que llamamos deuda técnica en próximas semanas). Y solo pueden pagarla uno de dos: el cliente o la empresa que desarrolló el software.
5. El cliente puede detectar la mala calidad del producto software
Si el cliente detecta mala calidad del producto software será el proveedor quien acabe pagando el trabajo mal hecho, aunque lo normal es que el cliente no se dé cuenta del mal desarrollo software por el que acaba de pagar y acabe pagando él mismo la mala calidad del desarrollador, que normalmente la paga en sobre exceso de horas de mantenimiento.
6. Las buenas prácticas no aseguran calidad del producto
Las buenas prácticas de ITIL, ISO 20000, lo son para detectar que los usuarios están teniendo problemas con en el software, las incidencias que los usuarios tienen con él, para organizar los pasos a producción de los parches, controlar cuantas veces “se ha caído” el software en producción, su disponibilidad, etc. Pero por muchos y muy buenos indicadores que tenga “tu coche” sobre si se está “calentando el motor”, “el aceite que queda”, etc., los problemas se reparan en “el motor” (el desarrollo software), no poniendo indicadores del nivel de servicio. Y el motor se arregla trabajando la calidad del producto software.
Una certificación de la calidad de los procesos no siempre asegura un producto de calidad.
Términos y bases más básicas de la calidad software
Según el Diccionario de la Real Academia Española de la Lengua, la calidad es (en sus cuatro primeras acepciones):
1. Propiedad o conjunto de propiedades inherentes a algo, que permiten juzgar su valor.
2. Buena calidad, superioridad o excelencia.
3. Carácter, genio, índole.
4. Condición o requisito que se pone en un contrato.
Aunque coloquialmente podría parecer más adecuada la segunda definición a la hora de evaluar la calidad de un producto o un servicio (ya que se pretende –en sentido absoluto– la “excelencia”), las organizaciones están interesadas en la primera y tercera acepción de calidad.
En efecto, se intenta determinar las propiedades inherentes a una cosa que nos permita conseguir que sea mejor que las otras, pero esto será relativo, ya que dependerá del punto de vista utilizado.
Por otra parte, las organizaciones deberán asegurar los requisitos que se fijan en los contratos.
Históricamente, los diferentes gurús de esta área han dado diversas definiciones de calidad (Hoyer y Hoyer, 2001):
W.A. Shewhart: “Existen dos aspectos de la calidad. El primero tiene que ver con la consideración de la calidad de una cosa como una realidad objetiva independiente de la existencia del hombre. La otra tiene que ver con lo que pensamos, sentimos o creemos como resultado de la realidad objetiva. En otras palabras, hay un lado subjetivo de la calidad” (1931).
Philip B. Crosby: “La primera suposición errónea es que calidad significa bondad, lujo, brillo o peso. La palabra «calidad» se utiliza para significar el valor relativo de las cosas en frases como «buena calidad», «mala calidad» y la expresión «calidad de vida”. «Calidad de vida» es un cliché porque cada oyente asume que la persona que habla entiende exactamente lo que para él significa la frase. Esta es precisamente la razón por la que debemos definir calidad como «conformidad con los requisitos» si queremos gestionarla” (1979).
Genichi Taguchi: “La calidad es la pérdida que un producto causa a la sociedad después de ser entregada… además de las pérdidas causadas por su función intrínseca” (1979).
Armand V. Feigenbaum: “La calidad de producto o servicio puede ser definida como las características totales compuestas de producto y servicio de marketing, ingeniería, fabricación y mantenimiento por medio de las cuales el producto y servicio en uso cumplirá las expectativas del cliente” (1983).
Kaoru Ishikawa: “Debemos enfatizar la orientación al cliente… Cómo uno interpreta el término “calidad” es importante… Interpretado restringidamente, calidad significa calidad de producto. Interpretado ampliamente, calidad significa calidad de trabajo, calidad de servicio, calidad de información, calidad de proceso, calidad de división, calidad del personal –incluyendo trabajadores, ingenieros, directivos y ejecutivos–, calidad del sistema, calidad de la empresa, calidad de objetivos, etc.” (1985).
W. Edwards Deming: “La dificultad de definir calidad es traducir las necesidades futuras del usuario en características medibles, de manera que un producto pueda ser diseñado y producido para dar satisfacción al usuario al precio que paga… ¿Qué es calidad? La calidad sólo se puede definir en términos del agente” (1986).
Joseph M. Juran: “La palabra calidad tiene múltiples significados. Los dos significados que dominan el uso de la palabra son:
La calidad consiste en las características del producto que satisfacen las necesidades de los clientes y les proporcionan por tanto satisfacción con el producto.
Calidad consiste en ausencia de deficiencias…. Es conveniente estandarizar en una corta definición la palabra calidad como adecuación al uso” (1988).
Por otro lado, en las principales normas internacionales, la calidad se define como “el grado en el que un conjunto de características inherentes cumple con los requisitos” (International Organization for Standardization).
Otra definición interesante de calidad es la proporcionada por ISO 8402: “Conjunto de propiedades o características de un producto o servicio que le confieren aptitud para satisfacer unas necesidades expresadas o implícitas”.
Así se puede ver que la calidad no se trata de un concepto absoluto: el consumidor la juzga con todo relativismo en un producto.
En general (Piattini y García Rubio, 2003), es posible considerarla como un concepto multidimensional (referida a muchas cualidades), sujeta a restricciones (p. ej., depende del presupuesto disponible) y ligada a compromisos aceptables (p. ej., plazos de entrega).
Incluso, se puede considerar que no es ni totalmente subjetiva (porque ciertos aspectos pueden medirse) ni totalmente objetiva (ya que existen cualidades cuya evaluación sólo puede ser subjetiva).
Así pues, la calidad no es absoluta, es multidimensional. Además, la calidad suele ser transparente cuando está presente, pero resulta fácilmente reconocible cuando está ausente (por ejemplo, cuando el producto falla o el servicio es deficiente).
Referencias
Hoyer, R. W.; Hoyer, B. (2001). What is Quality? Quality Progress, 34(7), 53-62.
Piattini, M., & García Rubio, F. (2003). Calidad en el desarrollo y mantenimiento del software. Ra-Ma.
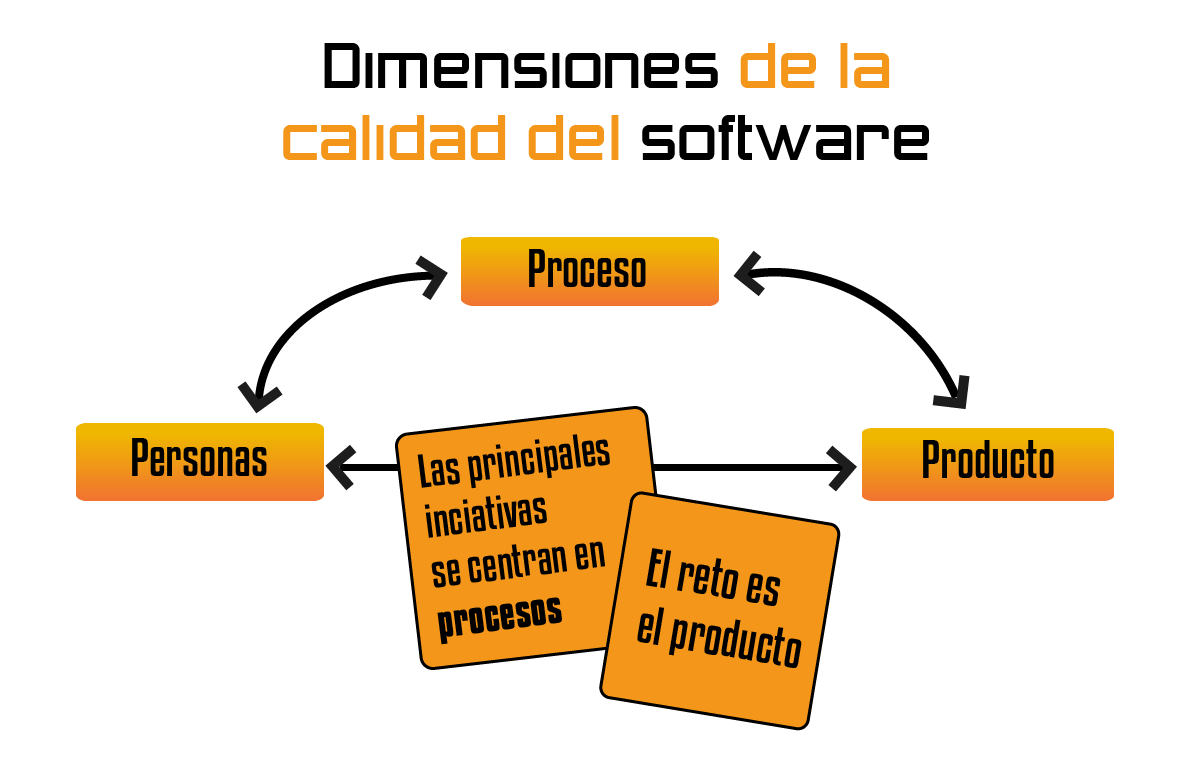
El concepto de calidad se subdivide, en tres tipos de calidad: la del proceso, la del producto y la de las personas/equipos
En el mundo del software, cuando nos referimos al amplio concepto de “calidad software” hemos de ser muy conscientes de que en realidad ese “etéreo” concepto de calidad se subdivide, principalmente, en tres tipos de calidad: la del proceso, la del producto y la de las personas/equipos.
A pesar de que este tema es muy antiguo, en el mundo empresarial es algo que no está tan claro y maduro. Y, a la hora de la verdad, cuando se entrega el software, aquello que en la oferta / contrato parecía tan claro resulta que produce enormes desengaños. Pero “¿cómo puede ser qué la empresa “x” con CMMI nivel “y” nos entregue este producto tan malo?” “¿No usaban la metodología “z”?”
Si quieres calidad en general, vas a necesitar conocer los tres ámbitos anteriores. Aunque depende del rol que juegues te puede importar más una perspectiva de calidad u otra. Si eres un cliente que solo compra software no puedes perder la prioridad, procesos, productos y personas son importantes, pero la calidad del producto es para ti determinante. Si eres fabricante de software, vas a necesitar los tres y no puedes olvidar ninguno.
Por todo esto, es preciso diferenciar y tener claro cuáles son las distintas áreas que abarca la calidad de software.
La calidad del proceso
La calidad vista desde el mundo de los procesos nos dice que la calidad del producto software está determinada por la calidad del proceso. Por proceso se entienden las actividades, tareas, entrada, salida, procedimientos, etc., para desarrollar y mantener software.
Modelos, normas y metodologías típicas aquí son CMMI, ISO 15504 / ISO 12207, el ciclo de vida usado; incluso las metodologías ágiles entran aquí.
La calidad del producto
Existen modelos de calidad de producto, destacando entre ellos la ISO 9126, o la nueva serie ISO 25000, que especifica diferentes dimensiones de la calidad de producto. Aunque aquí la dura tarea de evaluación recae en el uso de métricas software.
Este es el tema en el que se centra este curso, por lo que lo veremos en más profundidad a lo largo de las siguientes lecciones.
La calidad del equipo y/o personas
Si hubiese que elegir, de entre las claves que determinan el éxito (o fracaso) de un proyecto software, nos aventuraríamos a decir que ésta sería el papel que juegan “las personas”.
En mayor o menor medida, prácticamente todo aquel que ha estudiado el éxito o fracaso de un proyecto software ha destacado el papel que las personas, el equipo de desarrollo, juegan en el mismo. Concluyendo, en la mayoría de ocasiones, con que las personas son el factor más determinante.
Como decía Glass en su libro Facts and fallacies of software engineering Addison Wesley, no hay que olvidar que las personas son las que hacen el software. Las herramientas ayudan, las técnicas también, los procesos, etc. Pero sobre todo esto, están las personas. “Las personas son la clave del éxito”, que dijera Davis en su genial libro 201 principles of software development. El equipo humano que, como decía Cockburn en el artículo presentado en 4th International Multi-Conference on Systems, Cybernetics and Informatics (Orlando, Florida), “Characterizing people as non-linear, first-order components in software development”, es el componente no lineal de primer orden en el desarrollo software. Decía McConnell en el libroRapid development Microsoft Press que las personas son lo que tiene más potencial para recortar el tiempo de un proyecto, y que quienes han trabajo en software “han observado las enormes diferencias que hay en los resultados que producen entre desarrolladores medios, mediocres y geniales”.
Después de analizar 69 proyectos Boehm (lo explica en su libro Software engineering economics Prentice Hall PTR) comprobó que los mejores equipos de desarrolladores eran hasta 4 veces más productivos que los peores. Por su parte DeMarco y Lister, en su libro Peopleware, identifican diferencias de productividad de 5.6 a 1, extraídas de un estudio con 166 profesionales de 18 organizaciones. En la NASA [9], observaron diferencias de hasta 3 a 1 en productividad entre sus diferentes proyectos. E incluso mucho antes, en el 74, había ya estudios que habían observado diferencias de 2.6 a 1 en equipos a la hora de realizar las mismas tareas de desarrollo.
Pero aunque para algunos esto esté muy claro, no siempre es así en todos los proyectos. Hay empresas en las que se piensa que los desarrolladores no son lo más determinante, sino que son “piezas” intercambiables. Se piensa que lo único determinante es la parte comercial y la funcional, los técnicos son una “commodity”. De ahí que, en estas empresas, gran parte del equipo técnico no tenga el perfil, la cualificación y estudios acordes para desarrollar el software que se les encomienda, por cierto, una aplicación bastante grande.
Puede darse el caso también que los jefes de proyecto, y directores técnicos, jamás hayan estudiado alguna carrera técnica. Lo curioso en estos casos es que, aunque todo el mundo ve los grandes problemas de calidad software y de gestión del proyecto, nadie parece ver la principal causa de los mismos.
La gente que participa en un desarrollo software, no son como obreros en una cadena de montaje. No son tan fácilmente intercambiables, y el trabajo no es tan repetible como en estos otros trabajos. Más aún si no se ha implantado una calidad software de verdad (no sólo una certificación).
Podemos encontrar decenas de aproximaciones para mejorar la calidad de las personas, que van desde el tan de moda coaching, a la filosofía ágil de lograr la auto-organización de los equipos, estrategias de motivación, combinaciones de los anteriores, etc. E incluso hasta hay modelos, como son los TSP y PSP.
Cockburn, A. (2000). Characterizing people as non-linear, first-order components in software development. En 4thInternational Multi-Conference on Systems, Cybernetics and Informatics, Orlando, Florida.
Davis, A. M. (1995). 201 principles of software development. McGraw-Hill.
DeMarco, T., Lister, T. & House. (2013). Peopleware: Productive Projects and Teams. Addison-Wesley.
Glass, R. L. (2003). Facts and Fallacies of Software Engineering. Addison-Wesley Professional.
McConnell, S. (2010). Rapid Development: Taming Wild Software Schedules. Microsoft Press.
Una métrica es una asignación de un valor a un atributo (tiempo, complejidad, etc.) de una entidad software, ya sea un producto (código) o un proceso (pruebas).
Otro de los aspectos a destacar de la teoría de la medición es la distinción que establece entre medidas base (o directas) y derivadas (o indirectas).
Una medida base es “una medida de un atributo que no depende de ninguna otra medida, y cuya forma de medir es un método de medición”, por ejemplo, LCF (líneas de código fuente escritas), HPD (horas-programador diarias), CHP (coste por hora-programador, en unidades monetarias). Mientras que una medida derivada es una “medida que es derivada de otra medida base o derivada, utilizando una función de cálculo como forma de medir”. Ejemplos de medidas derivadas son: HPT (horas-programador Totales = sumatorio de las HPD de cada día), LCFH (LOC por hora de programador), CTP (coste total actual del proyecto, en unidades monetarias, que es el producto del coste unitario de cada hora por el total de horas empleadas).
También se pueden distinguir los indicadores que son “medidas derivadas de otras medidas utilizando un modelo de análisis como forma de medir”, por ejemplo, PROD (productividad de los programadores).
En cuanto a las formas de medir, un método de medición es “la forma de medir una medida base, y se puede definir como la secuencia lógica de operaciones, descritas de forma genérica, usadas para realizar mediciones de un atributo respecto de una escala específica”. Por ejemplo, contar líneas de código o anotar cada día las horas dedicadas por los programadores al proyecto. La forma de medir de las medidas derivadas es utilizando una función de cálculo (algoritmo o cálculo realizado para combinar dos o más medidas base y/o derivadas), como, por ejemplo, LCFH = LCF / HPT, medida derivada definida en base a 2 medidas base.
La forma de medir un indicador es mediante un modelo de análisis, que lo podríamos definir como “un algoritmo o cálculo realizado para combinar una o más medidas (base, derivadas o indicadores) con criterios de decisión asociados”. Un criterio de decisión “estará compuesto por valores umbral, objetivos, o patrones, usados para determinar la necesidad de una acción o investigación posterior, o para describir el nivel de confianza de un resultado dado”, por ejemplo, LCFH/LCFHvm< 0’70 →PROD=’muy baja’.
Complejidad ciclomática y código repetido
Si me dijeran que tengo que ir a una isla desierta y que solo me puedo llevar dos métricas de calidad software, sin duda, me llevaría el “porcentaje de código duplicado” y “la complejidad ciclomática”.
Sólo con esas dos métricas sería capaz de, en pocos minutos, podré hacerme una idea de la calidad de cualquier software que se me ponga por delante, por muchas líneas de código que tenga.
Estas métricas se obtienen de los fuentes de la aplicación, no de documentos o diseños en papel, y por ello reflejan fielmente la realidad.
Además, ambas métricas se pueden calcular para cualquier lenguaje de programación (Java, C#, Php, PL, etc.) y para cualquier paradigma (OO, estructurado, etc.) y son automatizables y económicas, ya que muchas herramientas de software libre las calculan.
Por último, esas dos métricas se obtienen del código… pero me dicen cómo está el diseño.
Código repetido
Hay quien dice que el código repetido es el peor enemigo de la mantenibilidad (es decir, que provoca gastar muchos euros de más, innecesarios, para hacer cambios) software (así lo comenta Fowler en su libro de Refactoring.
En mi vida profesional he visto auténticas barbaridades en este punto, aplicaciones software tremendamente obesas con disparatados porcentajes de código “copy pegado” repartido por decenas de fuentes. Lo que había disparado en muchos miles de euros los costes de mantenimiento.
Un alto porcentaje de código repetido:
Aumenta innecesariamente el número de líneas de código (a más líneas de código más complejo es el mantenimiento, y más costoso).
Dispara los costes (si hay que cambiar ese código repetido… hay que cambiarlo en muchos sitios).
Aumenta los riesgos (hay que buscar todas las repeticiones y si se nos olvida cambiarlo en algún sitio… el software acaba siendo incoherente).
Fue en 1976 cuando Thomas McCabe publicó un artículo en el que argumentaba como la complejidad del código puede obtenerse desde su flujo de control, o dicho de una manera más exhaustiva del número de rutas linealmente independientes del código, definiendo para ello una de las métricas más útiles en ingeniería del software, y que denominó “complejidad ciclomática”. En sí el concepto no era nuevo, ya que supone la adaptación de la prueba general de compresibilidad de Flesch-Kincaid (que suena raro, pero es bastante conocida en mediciones de la comprensibilidad de un texto), pero supuso una gran aportación al diseño software. No voy a entrar en su cálculo, ya que hay numerosos sitios donde lo explican.
De manera general es un síntoma que nos ayuda a determinar muchas de las posibles enfermedades del software, como sobre coste de realizar evolutivos debido a la rigidez del diseño, carencias modulares del diseño, diseños estructurados en entornos orientados a objetos, etc. Existe una relación entre el esfuerzo (horas – hombre, coste) necesario para mantener la aplicación y la complejidad de su diseño.
Es mi favorita. La métrica estrella a la hora de rápidamente ver la calidad software de un montón de fuentes. Fácil de automatizar y proporciona mucha información.
Y ¿por qué es tan importante y aún la citamos?
Permite apreciar la calidad del diseño software, de una manera rápida y con independencia del tamaño de la aplicación. Es una medida esencial cuando necesitas “tomar la temperatura” de un diseño software (más si estás realizando una auditoría externa y no conocías de antes la aplicación) de un tamaño considerable, y que se puede obtener fácilmente y de manera automatizada.
También la hemos utilizado para planificar proyectos de mejora de grandes productos software, para priorizar las partes del diseño a mejorar.
Por otro lado, en muchas ocasiones, es base para calcular el valor de las mejoras del diseño, o el valor que aporta introducir un patrón o buena práctica.
Y, además, nos da el número de casos de prueba unitarios básicos para obtener una cobertura del 100%.
También una aproximación al grado de comprensibilidad del diseño.
Con la complejidad ciclomática no se te van a escapar aquellos mortales algoritmos con muchos “case” o “switch”, con muchas cláusulas, o muchos ifs anidados, etc., que no son más que el reflejo de un mal diseño.
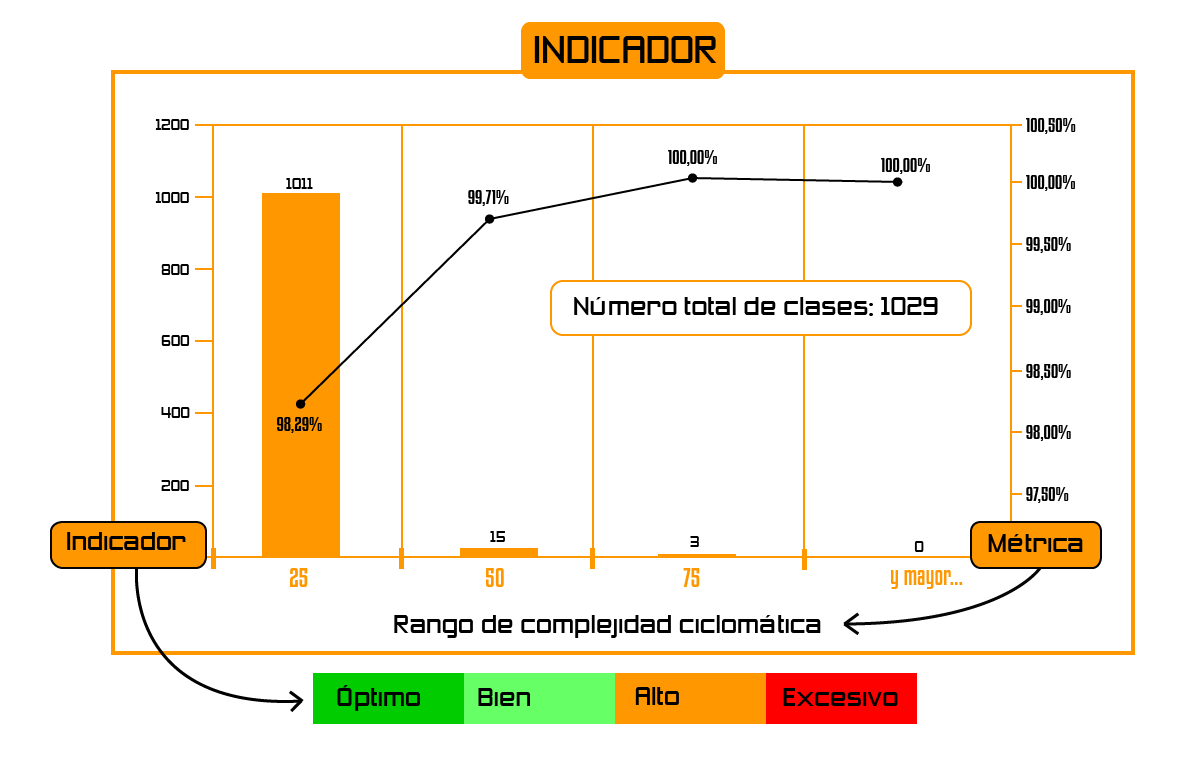
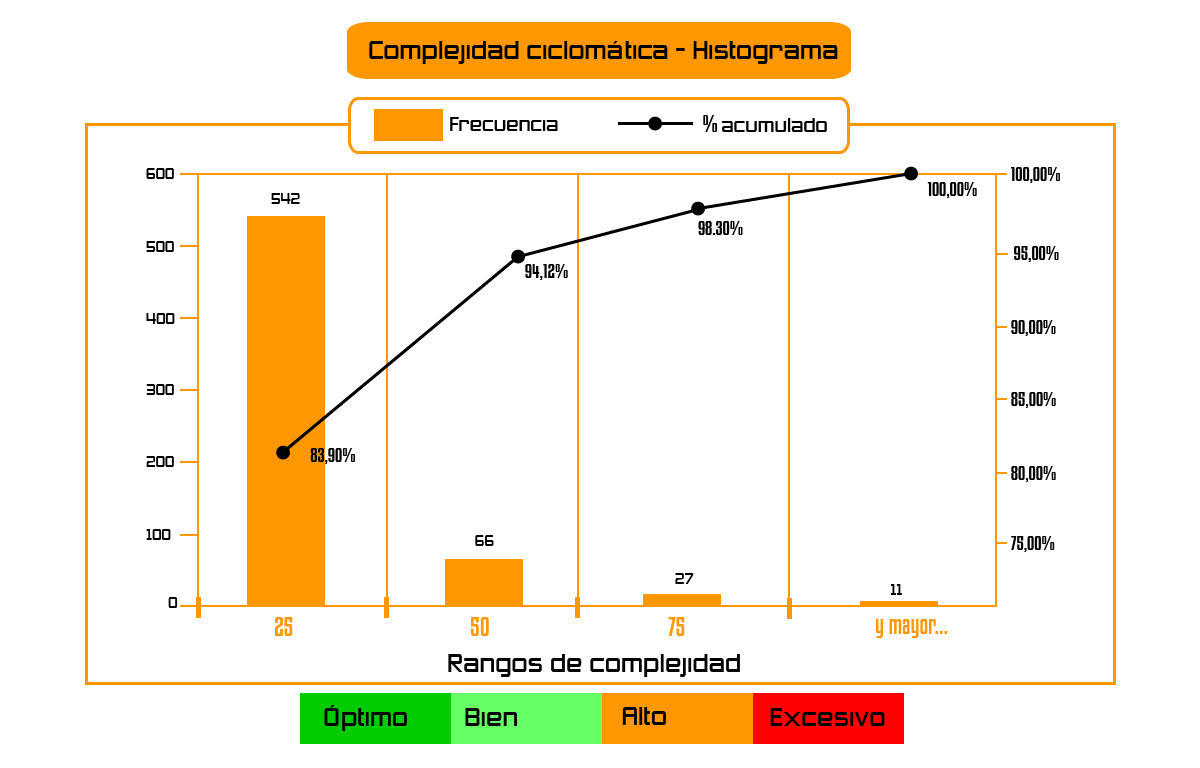
En el ejemplo de la figura podemos ver como 38 clases del diseño superan los 50 puntos de complejidad.
Esto quiere decir que cada una de estas 38 clases tiene más de 50 de estos saltos.
Lo que supone:
a) entender un código con más de 50 bifurcaciones
b) que para probar 100% la clase tengo que hacer más de 100 pruebas.
Referencias
Fowler, M., Beck, K., Brant, J.,Opdyke, W., & Roberts, D. (2012). Refactoring: Improving the Design of Existing Code. Addison-Wesley
McCabe T. J. (1976). A complexity measure. IEEE Trans. Software Eng, SE-2, 308 -320.
Cuándo deberías hacer los pasos a producción dentro de un Sprint o iteración
Os vamos a contar una situación muy típica con la que seguro muchos os vais a sentir identificados, y que trata sobre los desajustes y dudas que se producen a la hora de cerrar un sprint, o una iteración, y hacer un paso a producción.
La historia comienza con algo muy común, la siguiente situación: a la mayoría de equipos, o empresas, les gusta hacer los pasos a producción los viernes por la noche. Situación especialmente típica en empresas cuyo producto software se basa en la web.
Por si alguien muy junior, aún no fogueado en las batallas del mundo del software, estuviera leyendo este post y no supiera qué es un paso a producción, lo voy a resumir mucho diciendo que es la acción de poner una nueva versión de software a disposición de los usuarios reales del mismo.
Las razones de pasar a producción los viernes por la tarde noche suelen ser dos, que suelen venir juntas
1. Normalmente, estos equipos hacen alguna parada en el software (es decir, interrumpen el servicio que da) que ahora está en producción para poner la nueva versión. Y hacen los pasos a producción viernes noche, para parar cuando menos tráfico hay, por si hay algún problema y la parada se alarga, así afectan a menos usuarios.
2. A la mayoría de los equipos les gusta hacer coincidir el final de un sprint o iteración con el final de una semana, es decir, terminar un viernes. Y, normalmente, los viernes antes de la hora de la comida, ya que en algunos sitios los viernes por la tarde no se trabaja.
Lo anterior, lógicamente, crea una situación, llamemos… extraña. Si el sprint termina el viernes por la mañana y hacéis las reuniones típicas de final del sprint (la de revisión de sprint, con su demo correspondiente, y la retrospectiva) el viernes por la mañana, siendo el paso a producción el viernes por la noche… el paso a producción está fuera del Sprint.
Cuando en algún sitio veo la situación anterior, asumo, lógicamente, que, al estar el paso a producción está fuera del Sprint el Product Owner en su definición de “qué es necesario para terminar este Sprint” (te recomiendo leer aquí lo de en un proyecto ágil, acordar una buena definición de lo que significa terminado, el done) dijo que para terminar con éxito el Sprint NO era necesario pasar a producción.
De hecho, la demo de la reunión de revisión de sprint no puede mostrar las nuevas funcionalidades desarrolladas en producción (se pasa a producción por la noche y esta reunión es por la mañana). Cuando algún equipo me pide ayuda para mejorar su proyecto, en base a un ciclo de vida ágil, y expongo cómo afrontan este problema… muy pocos me saben responder cómo y por qué les pasa esto. Algunos equipos ni se lo habían planteado.
Los pasos a producción están en tierra de nadie, se hacen entre sprints
Realmente, esto no tiene por qué ser un problema, o sí, siempre y cuando asumamos todos que terminar un sprint con éxito, y sus correspondientes historias de usuario y tareas, no implica el paso a producción (y todo aquello que allí pase). Pero, claro, expuesto así… a algunos responsables y Product Owners esto no les gusta mucho…. “¿Terminar sin un paso a producción?”
Como consecuencia de lo anterior, hay quien hace otra nueva reunión para revisar la versión en producción desarrollada en el sprint previo dentro del siguiente sprint, los lunes, por ejemplo.
Pero, claro, esta reunión de los lunes para revisar el paso a producción debería ser antes de la planificación del siguiente sprint, porque si de dicha revisión salen nuevas tareas, esas nuevas tareas deben contemplarse en la reunión de planificación del sprint que empieza el lunes. Si se hace al revés, primero reunión de planificación de sprint y luego revisión del paso a producción, pueden pasar cosas raras, tareas derivadas de la revisión del paso a producción que entran en el sprint sin haber sido planificadas, etc.
Si empiezan a aparecer muchas tareas nuevas, detectadas en la revisión del paso a producción del lunes, la que revisa el paso a producción del viernes anterior, aparecen los nervios, y hay quien alarga el sprint (que ya te comenté en su día quedeberían todos los sprint, o las iteraciones, durar el mismo tiempo y, como ves, esto es un síntoma de que algo puede ir mal).
Como ves, por no extenderme mucho, pasan cosas raras que cuando las expones la gente se quedan pensando un rato y no sabe qué contestar. Y esto no es bueno para una planificación, cuanto más clarito esté todo mucho mejor.
Tres soluciones (dos fáciles, otra difícil)
La fácil. Lo razonable es que el paso (o pasos, ya llegaremos a eso) a producción sea previo al fin de sprint, que esté dentro del “done” que determina la correcta finalización de un sprint.
Si haces los pasos a producción los viernes noche, y quieres evitar los anteriores problemas, una opción es hacer la revisión de sprint y la demo los lunes.
Lo anterior resuelve vacíos en la planificación, pero genera tres reuniones el lunes, uf, la de fin de sprint, la retrospectiva y la de planificación del siguiente sprint.
En este punto hay quien se plantea, mover los pasos a producción los jueves, así, el viernes se realizará la reunión de revisión del sprint, posteriormente al paso a producción, y el “done” del sprint puede, correctamente, contemplar que las cosas terminan si están en producción.
El problema ahora es el que contaba al principio, tienes que pasar a producción un día de mayor tráfico y usuarios… un jueves.
La tercera solución viene del principal problema de todo esto… dejar para el final el paso a producción y, además, el paso a producción de todo. Un gran paso a producción de todo al final. Y un paso a producción que implica una parada.
Claro, si el paso a producción no fuese el gran final de todo, si no nos diese miedo hacerlo, y fuese una actividad más, rutinaria, algo no tan grande… esto no pasaría.
Te estoy hablando de hacer pequeños pasos a producción, de manera frecuente, durante el sprint, cada vez que se termina una funcionalidad o historia de usuario. Y sin parada.
A muchos al escuchar lo anterior se les queda la cara blanca… ¿hacer muchos pasos a producción en un sprint?
Lo sé, esto no está al alcance de cualquiera, requiere de un proceso de integración continua, de un proceso de pruebas robusto, de que no se puede ser ágil si se prueba en cascada (aunque uses Scrum, iteraciones o Sprints), de una arquitectura preparada para pasar a producción sin paradas, es lo que viene a llamarse “entrega continua”, algo tan deseado como difícil para algunos, pero que si lo logras situará a tu equipo y a tu empresa muy por encima.
Por qué la gestión de versiones es imprescindible. Una experiencia real ilustrativa
No suena tan “cool”, ni tal ágil, ni tan data, ni tan cloud, ni tan lean. Pero siempre lo repetiré: no existe un proyecto software que funcione mínimamente bien (en lo que refiere a calidad, productividad y tranquilidad) sin una buena gestión de la configuración y control de versiones.
Es decir, y sin perdernos en definiciones, que si no controlas correctamente los cambios que se realizan en los productos del ciclo de vida, el cómo varias personas trabajan a la vez sobre, por ejemplo, los mismos fuentes, cómo gestionar diferentes versiones del mismo producto en producción en diferentes clientes, cómo una vez solucionado un cambio en una versión se replica el parche en el resto versiones para no arrastrar errores, etc. Si no tienes una estrategia para lo anterior, acabarás, como poco, duplicando el número de personas del equipo (euros) o perderás el control del software (euros).
Experiencias reales terroríficas te podría contar decenas (pérdida de fuentes, bugs reparados que vuelven a aparecer, programadores que no pueden trabajar mientras los tester prueban, etc.) porque me he encontrado casi de todo, y supongo que aún me queda por ver. Pero por no entristecerte mucho el día, te voy a dejar sólo una…
Recuerdo que hace ya muchos años “me invitaron” a revisar la calidad del desarrollo de un proyecto. El responsable del departamento quería que le diera mi opinión, ya que a él le parecía que el equipo era poco productivo, vamos que había demasiada gente para el trabajo que se hacía, y que se le estaban disparando los costes de mantenimiento del producto software que desarrollaban.
Como en “toda casa de vecino”, había muchas cosas que se podían mejorar, pero lo que más me llamó la atención era un grupo de gente llamado el “equipo de replicación”. Y siempre que aparecen equipos transversales con nombres poco claros… algo raro pasa.
Resulta que el famoso equipo de replicación hacía lo siguiente: llegaba un bug, desarrollo lo solucionaba en una versión del software que había igual a la que tenía en producción el cliente que reportó el error… y una vez solucionado el bug el equipo de replicación se encargaba de buscar “a mano” y corregir ese mismo bug en más de veinte versiones software, que supuestamente eran igual a la anterior, pero que estaban en repositorios separados, había un repositorio separado por cliente, pero teniendo todos el mismo producto software.
En vez de una rama principal, y ramas para versiones, estabilización, “merges”, etc., había realmente más de 20 versiones en más de 20 repositorios diferentes.
Así claro que se necesitaba un equipo de replicación. Porque no se desarrollaba un producto con varias versiones… se mantenían más de 20.
Por si te interesa saber cómo terminó la historia, al final, con tanto lío, realmente las múltiples versiones ya no eran muy iguales, porque la mitad de bugs no se replicaban por tiempo, y tampoco se conocían las diferencias entre ellas, lo que se juntó con que era inviable el coste de “replicación”.
La empresa se quedó sin dinero, se prescindió de las personas del equipo de replicación, se dejó de “replicar”, y se asumió que de por vida habría que mantener muchos productos (euros), ahora diferentes, pero a la vez similares.
Por esto, y por muchas otras historias, siempre digo que la gestión de la configuración y el control de versiones son imprescindibles. Si yo pudiera, metería en cada una de las Universidades, en cada escuela de informática, una asignatura obligatoria sólo de gestión de la configuración.
No hay excusa, hay expertos en el tema, hay decenas de libros (te recomiendo encarecidamente leer el que para mí es el mejor libro sobre el tema,Configuration Patterns de Berczuk y Appleton) que cuentan cómo gestionar como Dios manda las versiones, hay patrones, el área es madura, hay herramientas, las hay de software libre.
Referencia
Berczuk, S.P., & y Appleton, B. (2003). Software Configuration Management Patterns: Effective Teamwork, Practical Integration. Addison-Wesley Professional.
¿Qué estrategia de control de versiones seguir en un equipo Scrum?
El uso del control de versiones, y más concretamente que todo el equipo siga una correcta estrategia de versionado, es la base imprescindible de cualquier proyecto.
Pero muchas veces suelen surgir dudas sobre qué estrategia de control de versiones llevar a cabo en un equipo Scrum. ¿Cómo gestionamos el control de versiones cuando trabajamos por historias de usuario o tareas? ¿Dónde entra la integración continua? ¿Cómo podemos combinar historias de usuario, tareas, control de versiones e integración continua?
Lo cierto es que no hay un único enfoque para tratar todo esto. Lo que voy a hacer es contarte un poco las principales estrategias de control de versiones que hay, cómo combinarlas con el trabajo de Scrum y la integración continua y cuál creo que es la mejor.
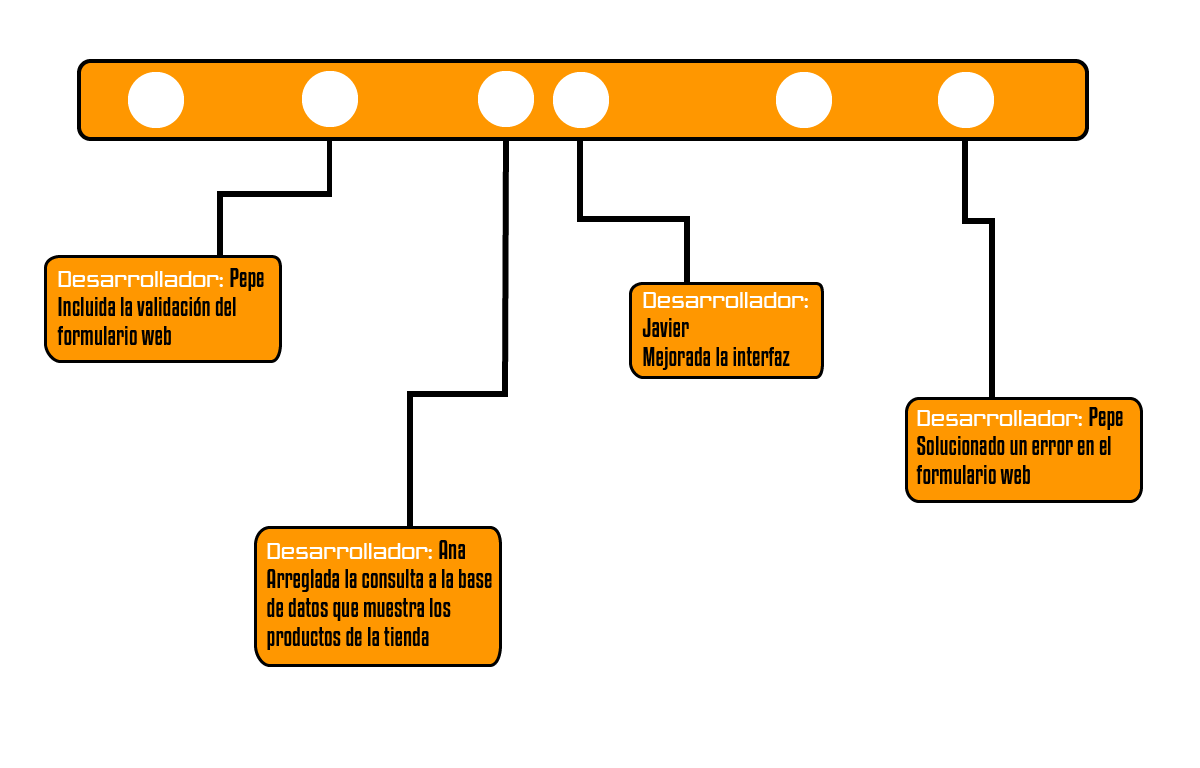
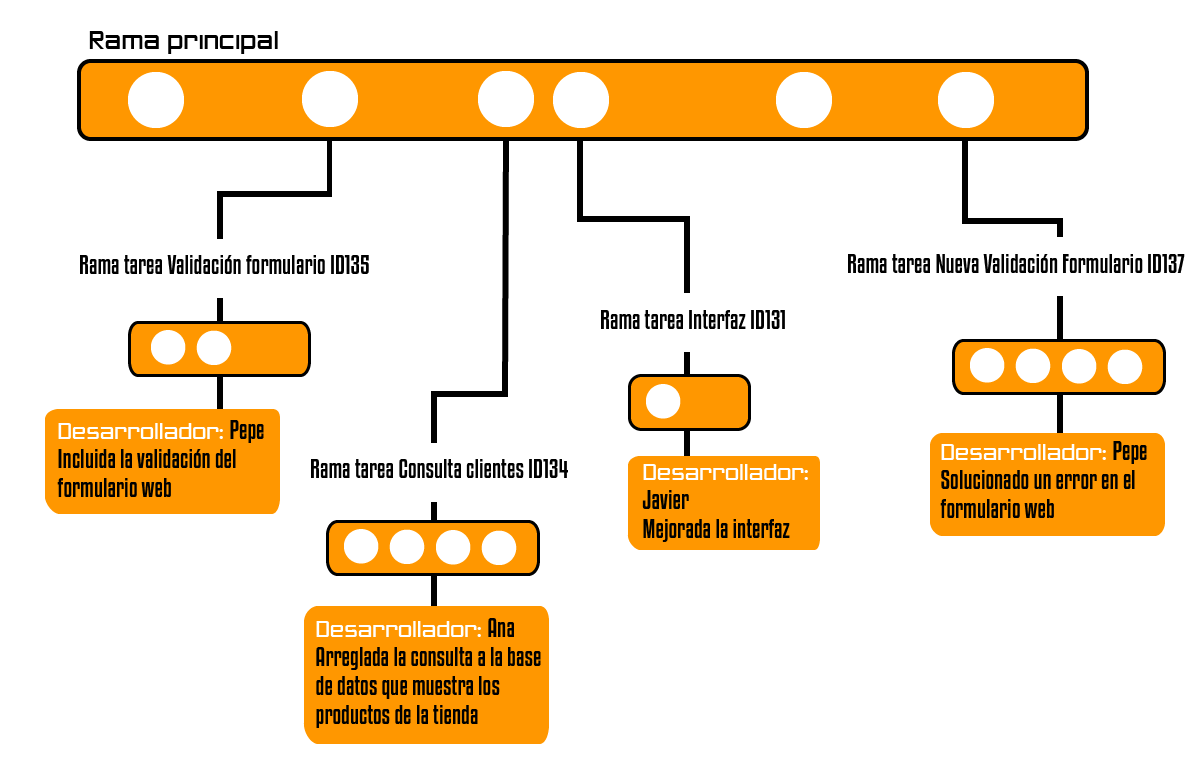
Lo primero, es que en cuanto a técnicas de versionado se refiere, se distinguen dos alternativas: desarrollar en una única línea de control de versiones (desarrollo lineal) o en paralelo, utilizando varias ramas. Desarrollo lineal en el control de versiones Esto sería un desarrollo lineal, en una única línea del control de versiones. Todos los desarrolladores van subiendo las tareas que han terminado a la misma línea del control de versiones.
Uno de los principales problemas que tiene este enfoque es que los errores se propagan más fácilmente. Como puedes ver en la figura anterior, Pepe introduce un error al principio, que luego consigue solucionar. No obstante, para cuando lo hace, tanto Ana como Javier han continuado desarrollando con el código antiguo, el que tenía el error, por lo que no podemos estar seguros de que esta línea principal tenga una versión estable del código, posible candidata para un paso a un entorno de pruebas, producción etc.
Ahora ambos tendrán que hacer un esfuerzo mayor para combinar la parte nueva de Ana y Javier, con la parte de Pepe sin el error.
Además, por este motivo, puede que los desarrolladores no suban su código al control de versiones muy a menudo, hasta que no sea estable, por temor a introducir errores y que se propaguen a los otros desarrolladores. Con ello, incumplimos la recomendación de que todo el código esté en el control de versiones e integrar frecuentemente.
Integración continua y desarrollo lineal en el control de versiones
Un enfoque para la integración continua aquí podría ser que cuando un desarrollador intente subir su código a esta única línea principal, el servidor de integración continua intente compilar su código con el que ya hay en la línea principal y ejecutar los tests. Si todo es un éxito, el código se subirá correctamente al control de versiones, y si no, el desarrollador tendrá que solucionar los errores.
¿Qué pasa con este enfoque? Además de los problemas mencionados antes, ¿dónde se queda el código mientras que el servidor de integración continua está compilando y pasando los tests? Hasta que el servidor no termina, no se sube al control de versiones, por lo que puede que pasemos un tiempo sin hacer nada hasta recibir si todo ha sido un éxito o no.
Por ello, un enfoque que podría funcionar mejor es…
Desarrollo paralelo, o a través de ramas
Podemos cambiar el desarrollo lineal por un enfoque de una historia de usuario o tarea por rama, es decir, creamos una rama cada vez que vamos a desarrollar una tarea, una historia de usuario o solucionar un error. Cuando terminemos de implementar dicha tarea, el código esté probado y sea estable, procederemos a integrarlo en la rama principal o línea de desarrollo principal.
Si en nuestro proyecto trabajan varios equipos, por ejemplo front-end y desarrollo, crearemos una rama para front-end y otra rama para desarrollo y de cada una de ellas saldrán ramas para cada una de las tareas de los equipos.
De esta forma en la rama de desarrollo, tendremos el código estable e integrado de las tareas de desarrollo, y lo mismo en la rama de front-end con sus tareas correspondientes. Por último, en la rama principal, integraremos el código de desarrollo y de front-end, teniendo la garantía de que es una versión estable.
Estas ramas tienen que tener nombres descriptivos, como por ejemplo el nombre de la tarea, historia de usuario o el id del bug. Así mejoramos la trazabilidad del código, y se establece claramente qué propósito tiene cada rama.
Pero también tiene más ventajas:
Cada desarrollador puede subir su código al control de versiones (a la rama que creó para desarrollar su tarea) sin temor a estropear el código de la línea principal de desarrollo.
Da igual que la tarea no esté terminada, o tenga errores, su código estará a salvo en el control de versiones, para posteriormente ser perfeccionado, sin afectar a nadie más.
Además, reducimos la propagación de los errores. Si un desarrollador introduce un error en su código, que está en una rama separada, y no se da cuenta, se puede solucionar antes de integrarlo en la rama principal, sin afectar a posteriores desarrollos.
De esta forma también, garantizamos que el código que está en la línea principal de desarrollo sea estable. Todas las ramas/tareas que se desarrollen a partir de la rama principal, partirán de un punto estable, sin errores.
Por lo tanto, si al integrar una rama con la principal el código falla, acotamos el momento y lugar donde se ha producido el error. Sabremos que hemos sido nosotros quienes hemos introducido el fallo.
En relación con lo anterior, también aseguramos que las tareas son independientes unas de otras. Nuestro código parte de algo estable, y no depende de los fallos que la implementación de otras tareas haya introducido en el software final.
Integración continua y desarrollo paralelo en el control de versiones
En este enfoque, una alternativa es que el servidor de integración continua sea el que cuando terminemos una tarea o historia de usuario, combine la rama de esa tarea con la rama principal, y compruebe que pasan los tests.
Esa versión estable integrada puede etiquetarse como candidata estable para pasar al entorno de testing o producción.
Pero también podrían ser los propios desarrolladores los que se encarguen de pasar los tests y combinar la rama de la tarea con la línea principal, y el servidor de integración continua sea el que etiquete la versión estable como candidata para pasar a testing o producción.
Terminando…
Lo más importante de todo esto, es que te quedes con la idea de que existen otras alternativas a que todo el mundo suba el código a la misma línea del control de versiones.
Como ya hemos visto, perder el miedo a desarrollar en distintas ramas puede aportarnos muchas ventajas, por eso es recomendable que le eches un vistazo a esta estrategia. La elección de crear una rama para cada historia de usuario o una rama para cada tarea dependerá del equipo.
Tipos de pruebas
Uno de los principales objetivos es mejorar la calidad del software y que tu empresa pueda moverse rápido: desarrollar poco a poco y contrastar ese desarrollo con el cliente, para saber que vamos en buen camino y si no rectificar. Es por ello que se hacen diferentes tipos de pruebas, que se describen a continuación.
Pruebas unitarias
Empezamos a más bajo nivel, el de programación. Aquí encontramos las pruebas unitarias. Con ellas probamos las unidades del software, normalmente métodos. Por ejemplo, escribimos estas pruebas para comprobar si un método de una clase funciona correctamente de forma aislada.
Las pruebas unitarias corresponden a la visión de los desarrolladores, que son los que deben elaborarlas. Esto es así porque cuando programas código, tú eres el que mejor conoce y entiende ese código, y sabes qué debería realizar exactamente cada método.
Las dependencias complejas o interacciones con el exterior se gestionan realizando stubs (que son objetos que tienen un comportamiento programado ante ciertas llamadas de un test concreto) o mocks (objetos ya programados con los datos que se espera recibir).
Aquí nos interesa cómo funciona la unidad, no la interacción entre componentes (cosa que sería una prueba de integración).
Las ventajas de las pruebas unitarias es que por un lado los tests tardan menos tiempo en ejecutarse, por lo que se tiende a lanzarlos más a menudo. Además, las pruebas unitarias te fuerzan a escribir clases menos acopladas (con menos dependencias las unas de las otras), lo que mejora el diseño del software.
Si una prueba unitaria falla, sabes que es por un problema en el código. Para automatizar y realizar este tipo de pruebas se utilizan framework de tests, por ejemplo, JUnit en el caso de Java.
No obstante, no pienses que JUnit sirve exclusivamente para realizar pruebas unitarias, porque con JUnit se pueden realizar también otros tipos de pruebas.
Pruebas de integración
En este caso probamos cómo es la interacción entre dos o más unidades del software. Este tipo de pruebas verifican que los componentes de la aplicación funcionan correctamente actuando en conjunto.
Siguiendo con el caso anterior, las pruebas de integración son las que comprobarían que se ha mandado un email, la conexión real con la base de datos etc.
Este tipo de pruebas son dependientes del entorno en el que se ejecutan. Si fallan, puede ser porque el código esté bien, pero haya un cambio en el entorno.
Por ejemplo, también podríamos usar JUnit para realizar pruebas de integración, si no hacemos mocks o stubs, y nos centramos en probar el comportamiento de los componentes en su conjunto.
Pruebas de sistema
Lo suyo sería realizar este tipo de pruebas después de las pruebas de integración.
Aquí se engloban tipos de pruebas cuyo objetivo es probar todo el sistema software completo e integrado, normalmente desde el punto de vista de requisitos de la aplicación.
Aquí aparecerían las pruebas funcionales, pruebas de carga, de estrés, etc.
Pruebas funcionales
En este caso, el objetivo de las pruebas funcionales es comprobar que el software que se ha creado cumple con la función para la que se había pensado.
En este tipo de pruebas lo que miramos, lo que nos importan, son las entradas y salidas al software. Es decir, si ante una serie de entradas el software devuelve los resultados que nosotros esperábamos. Aquí solo observamos que se cumpla la funcionalidad, no comprobamos que el software esté bien hecho, no miramos el diseño del software. Estudiamos el software desde la perspectiva del cliente, no del desarrollador.
Por eso este tipo de pruebas entran dentro de lo que se llaman pruebas de caja negra: aquí no nos centramos en cómo se generan las respuestas del sistema, solo analizamos los datos de entrada y los resultados obtenidos.
Estas pruebas pueden ser manuales, o automatizarse con herramientas. Una de las más conocidas para web es Selenium, en sus distintas variantes.
Como ya vimos, en función del objetivo al que se orienten, las pruebas funcionales también pueden actuar como pruebas de regresión, smoke test etc.
Pruebas de carga
Las pruebas de carga son un tipo de prueba de rendimiento del sistema. Con ellas observamos la respuesta de la aplicación ante un determinado número de peticiones.
Aquí entraría por ejemplo ver cómo se comporta el sistema ante X usuarios que entran concurrentemente a la aplicación y realizan ciertas transacciones.
Pruebas de estrés
Este es otro tipo de prueba de rendimiento del sistema. El objetivo de estas pruebas es someter al software a situaciones extremas, intentar que el sistema se caiga, para ver cómo se comporta, si es capaz de recuperarse o tratar correctamente un error grave.
Pruebas de aceptación
Por último, las pruebas de aceptación se realizan para comprobar si el software cumple con las expectativas del cliente, con lo que el cliente realmente pidió. Para realizar las pruebas de aceptación actualmente se usa BDD.